




The demand for machine learning engineers and data scientists has increased exponentially over the years. This is justified because machine learning is being applied in almost every field to solve real-world problems.
There are very good programming languages like Python and R to acquire the skills required for machine learning engineers and data scientists. But people need to spend a good amount of time learning these programming languages before practising data analysis techniques.
Machine learning engineers and data scientists need to apply different visualisation techniques to understand the data and test different models to get accurate results. In this situation, having a GUI based tool that needs minimum programming can lead to good productivity.
This article introduces Orange, a visual programming software package released under GPL, and focused on components for data visualisation, machine learning, data mining, and analysis of data.
It features a visual programming front-end for explorative rapid qualitative data analysis and interactive data visualisation. The developers of Orange at the University of Ljubljana in Slovenia built the core components in C++ with wrappers in Python, which are available on GitHub. Orange is available for Mac, Linux and Windows users.
Let's see a simple demo of how we can use Orange to do machine learning tasks. Following steps are carried on MacOS, but they remain the same for Linux and Windows.
Prerequisites - All You Need
We are going to work in a virtual environment for this demo (considering we have python already installed, if not please check this). To create this environment follow the below steps in the terminal (make sure you are in a project folder and not in Desktop or Documents, just to avoid any other issues it might create):
~ % mkdir orange_proj
~ % cd orange_proj
orange_proj ~ % python3 -m venv venv
This creates a virtual environment in our working directory orange_proj if we notice there is a folder created named venv in the directory.
To activate this venv, we can do the following in the terminal:
orange_proj ~ % source venv/bin/activate
(venv) orange_proj ~ %
(venv) prefix in terminal means that this environment is active for us to do the work. Now, nothing outside of it will be affected and libraries will only be installed in this environment.
So moving on, first we upgrade the pip, setuptools and wheel packages in python's virtual environment (to avoid any unwanted errors).
(venv) orange_proj ~ % pip install --upgrade pip setuptools wheel
When you run the above command, it upgrades pip, setuptools and wheel in one go. Let's install Orange now.
(venv) orange_proj ~ % pip install orange3
After you hit enter on that, you should have orange installed in your virtual environment, if you faced any issues/errors please reach out to me in the comments.
Let's move on to the fun part now!
Starting Orange
Now, in the same virtual environment where we just installed Orange, we will type the following to launch Orange GUI.
(venv) orange_proj ~ % orange-canvas
After you hit enter it should open something like this:

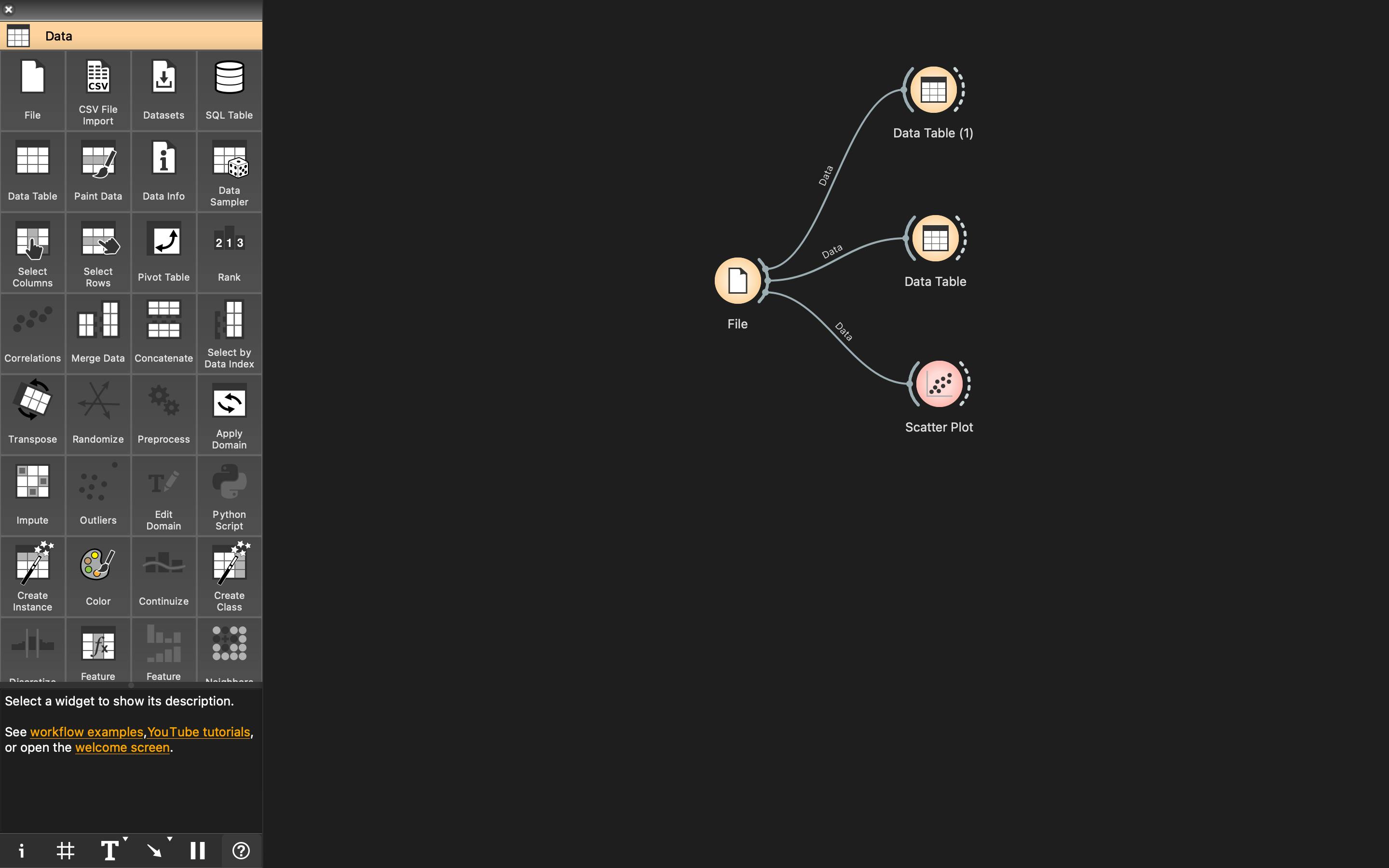
It offers a very simple GUI and is divided into 3 sections - categories, widgets and canvas. By default Orange comes with 5 categories called Data, Visualize, Model, Evaluate and Unsupervised.
To perform any kind of task with Orange, we need to construct a workflow by dragging widgets onto the canvas from the respective categories and connecting them by drawing a line from the transmitting widget to the receiving widget. These lines can be connected through an arc on sides of these widgets, the left arc represents the input and the right arc represents the output from that widget.
Let's build a classifier using Orange.
Load Dataset in Orange
Open Orange and drag the File widget icon under the Data category and place it on canvas wherever you want.

Data category widgets offer multiple options to load the data into Orange. It is not possible to introduce all those options in this article (better to take that as a learning activity after completing this article).
Double click on the File widget on canvas to load the dataset.
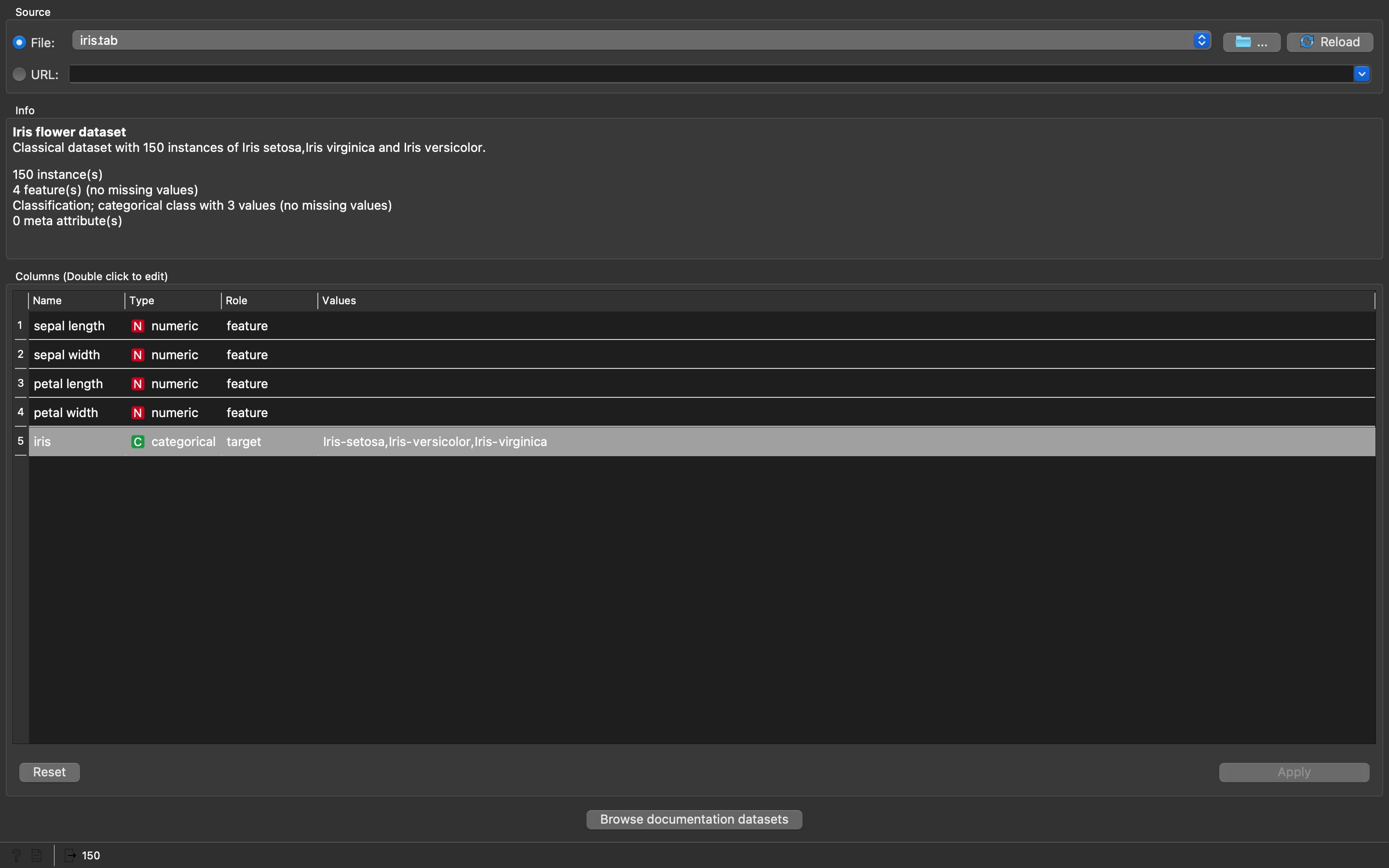
We are going to work with the basic, most loved dataset, Iris Dataset, that is by default selected, but if it is not then you can manually select it. The Iris dataset contains 150 samples with 5 features. Any feature can be skipped by clicking on the role and selecting skip. We can make any feature act as a target variable for predictions. Here, we make Species a target. Now simply close the window without worrying about anything else!
Explore Dataset in Orange
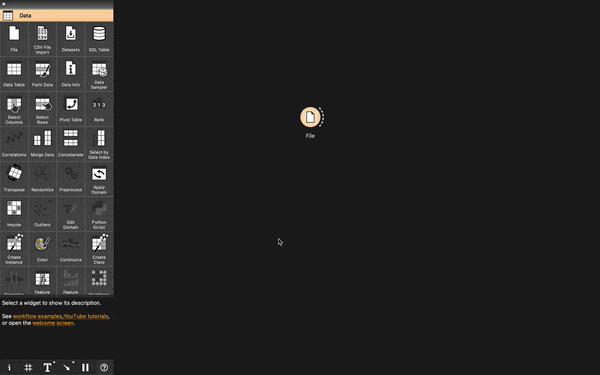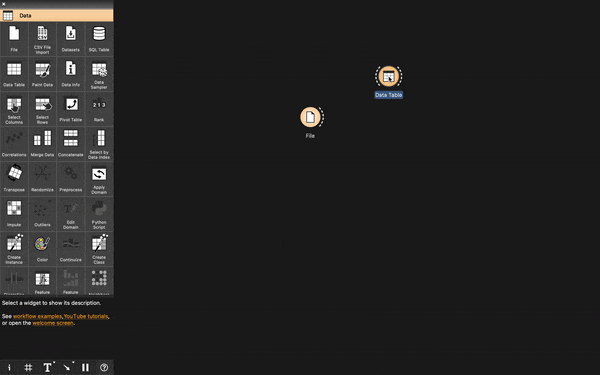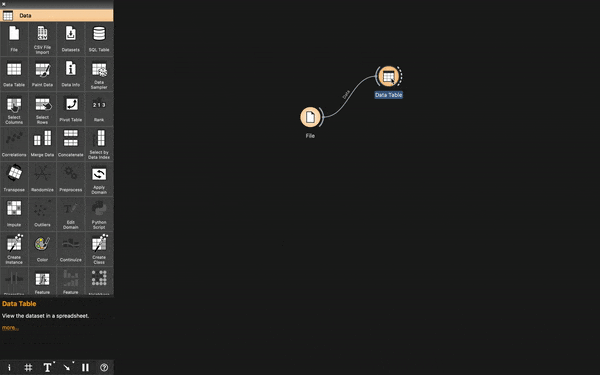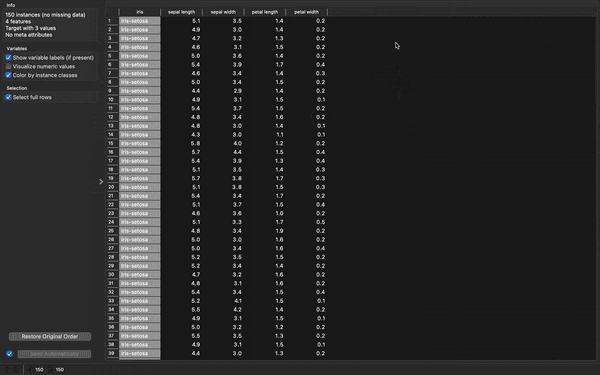
Now select and drag the Data Table widget from the Data category into the canvas and connect it with the File widget. Double click Data Table to view the spreadsheet output of the Iris dataset.
Let's plot a scatter plot for this dataset. Drag the Scatter Plot widget from the Visualize category, place it on the canvas and connect it with the File widget. Double click on the Scatter Plot widget to get the samples plotted on the graph.

Training And Testing Set in Orange
Machine learning classifiers take known samples (training data) and predict the output for any new unknown sample. At the outset, the machine learning classifier looks like a black box that takes some input sample and predicts the corresponding output label.
So let's prepare the training dataset for Iris data. Of the 150 samples, we will take 147 as training samples and 3 as testing data. To achieve that do the following:
- Double click on the
Data Tableon the canvas and select all the samples from the spreadsheet (Ctrl + A or Cmd + A). - Now, hold the
CtrlorCmdkey and deselect rows50th,100thand150th. If you see at the bottom of the spreadsheet you will know that we have 147 rows selected out of 150, this will act as our training dataset. This would look something like this:
- Now, leave it open and go back to the canvas. Drag another
Data Tablefrom theDatacategory and put it on the canvas and connect it withFile. The new data table would be automatically be named asData Table (1), leave it as it is.
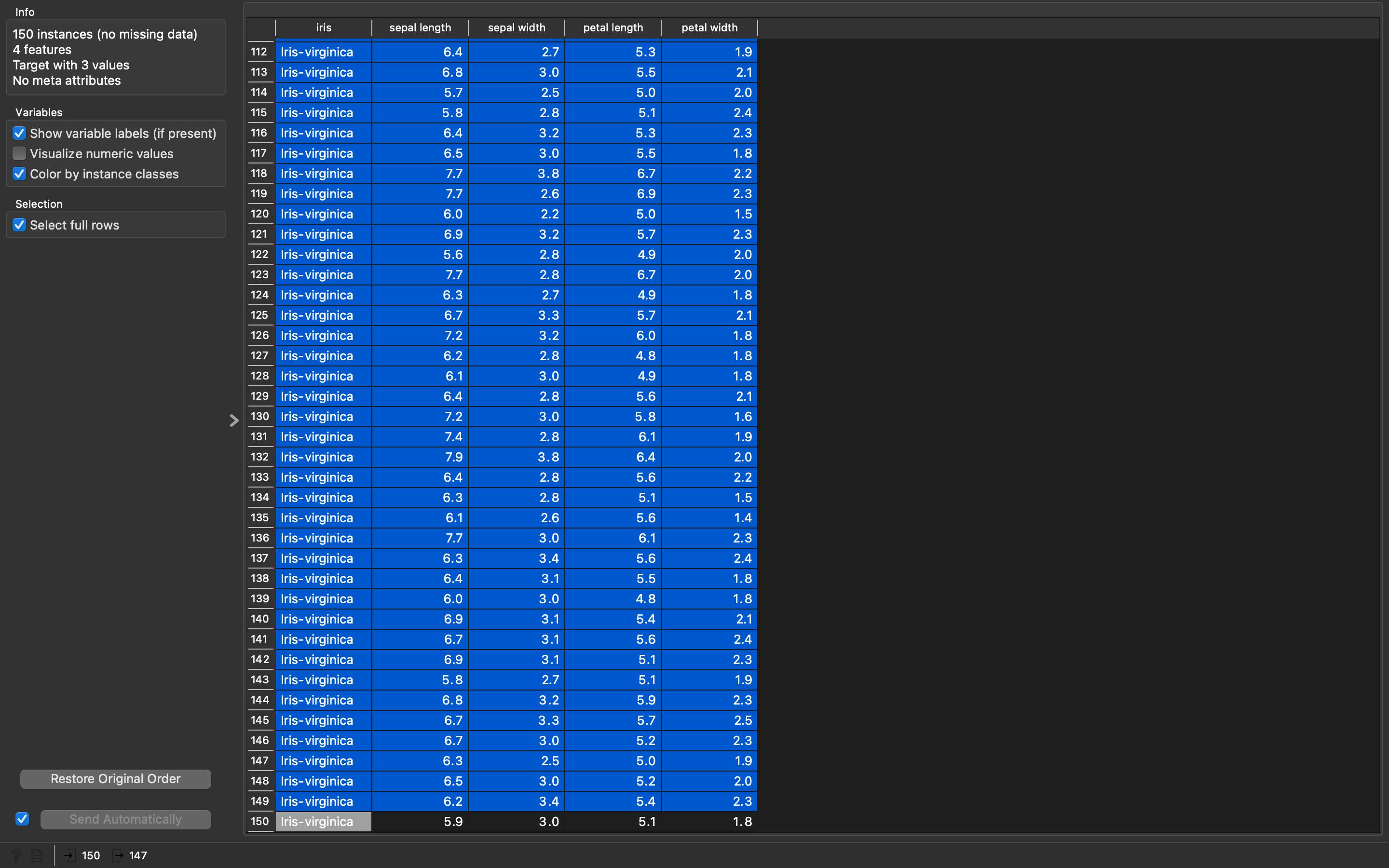
- Double click
Data Table (1)and you would be able to see a new spreadsheet of the Iris dataset. Now, here we will select our testing data. Select only those rows that we left for training, rows50th,100thand150th. If you see at the bottom of the spreadsheet you will know that we have 3 rows selected out of 150 rows. This will look something like this:
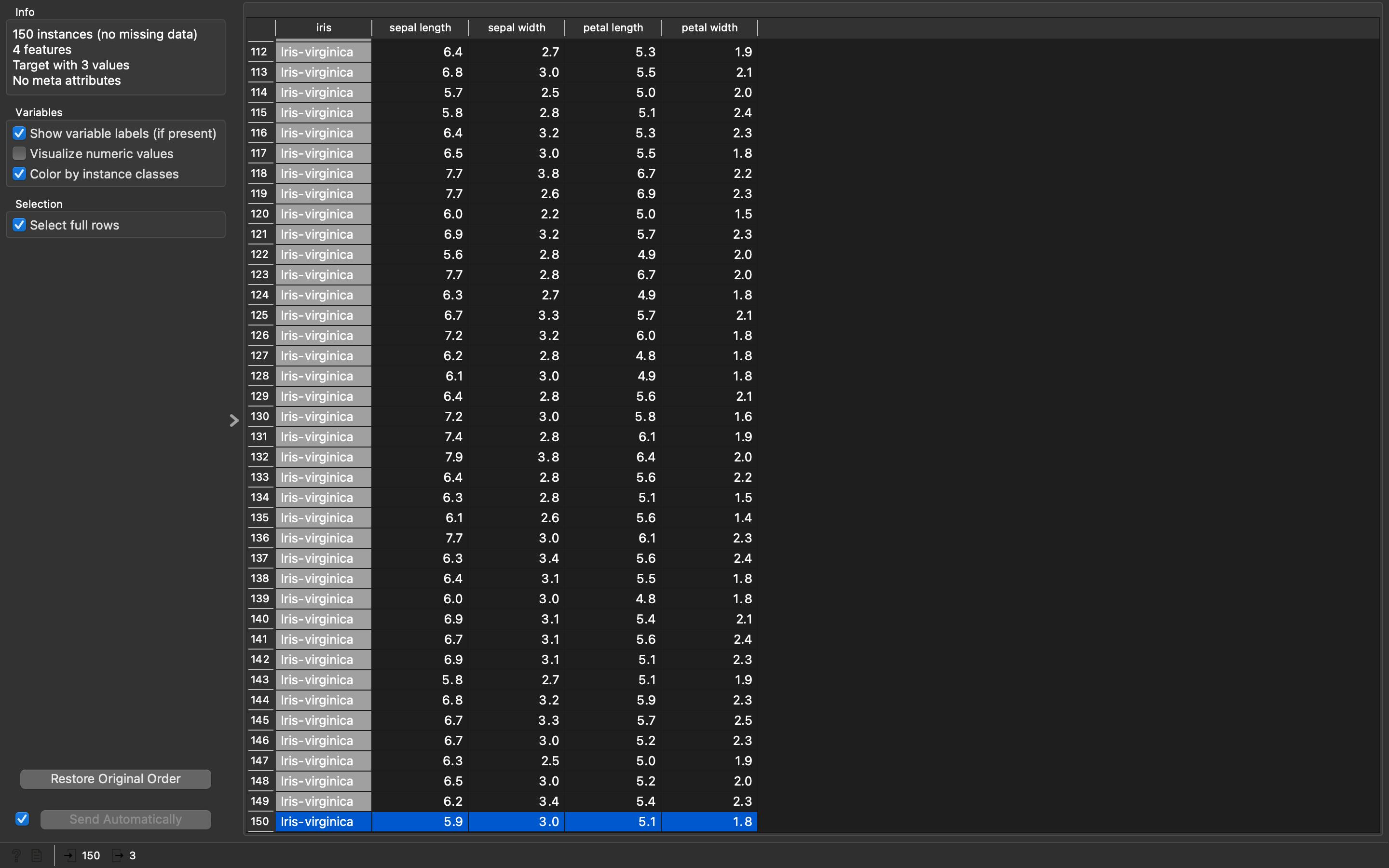
- Leave it open and move back to the canvas. Now we will do the model training and predictions on our training and testing dataset respectively.
Training and Predictions in Orange
Make sure we are on canvas window, with 2 data table spreadsheets open in the background (what we just did above).
Follow the below steps to perform training and prediction on the Iris dataset:
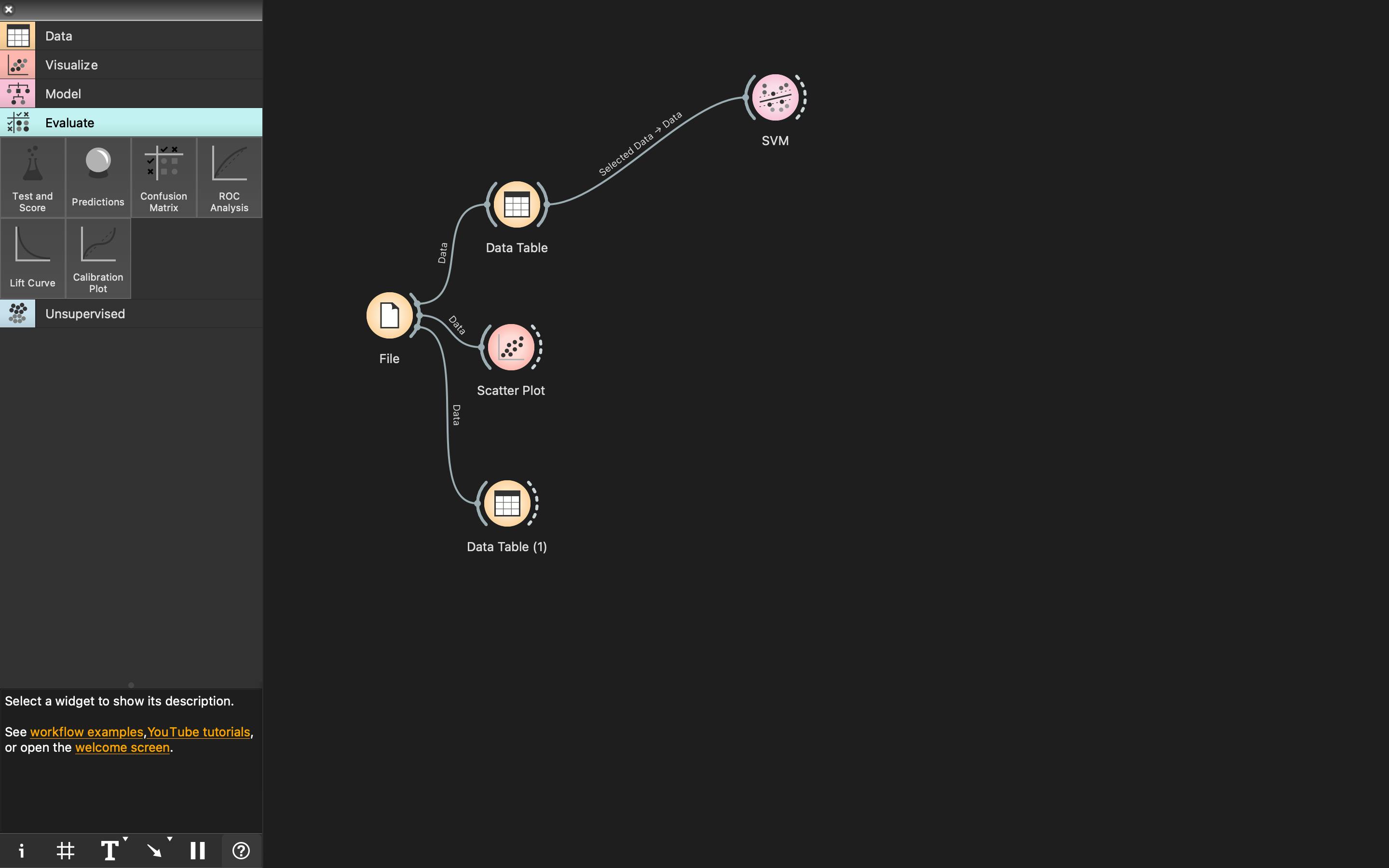
- Select and drag the
SVMwidget from theModelcategory to the canvas. - Connect the
Data Tableoutput to theSVMwidget. It would look something like this.
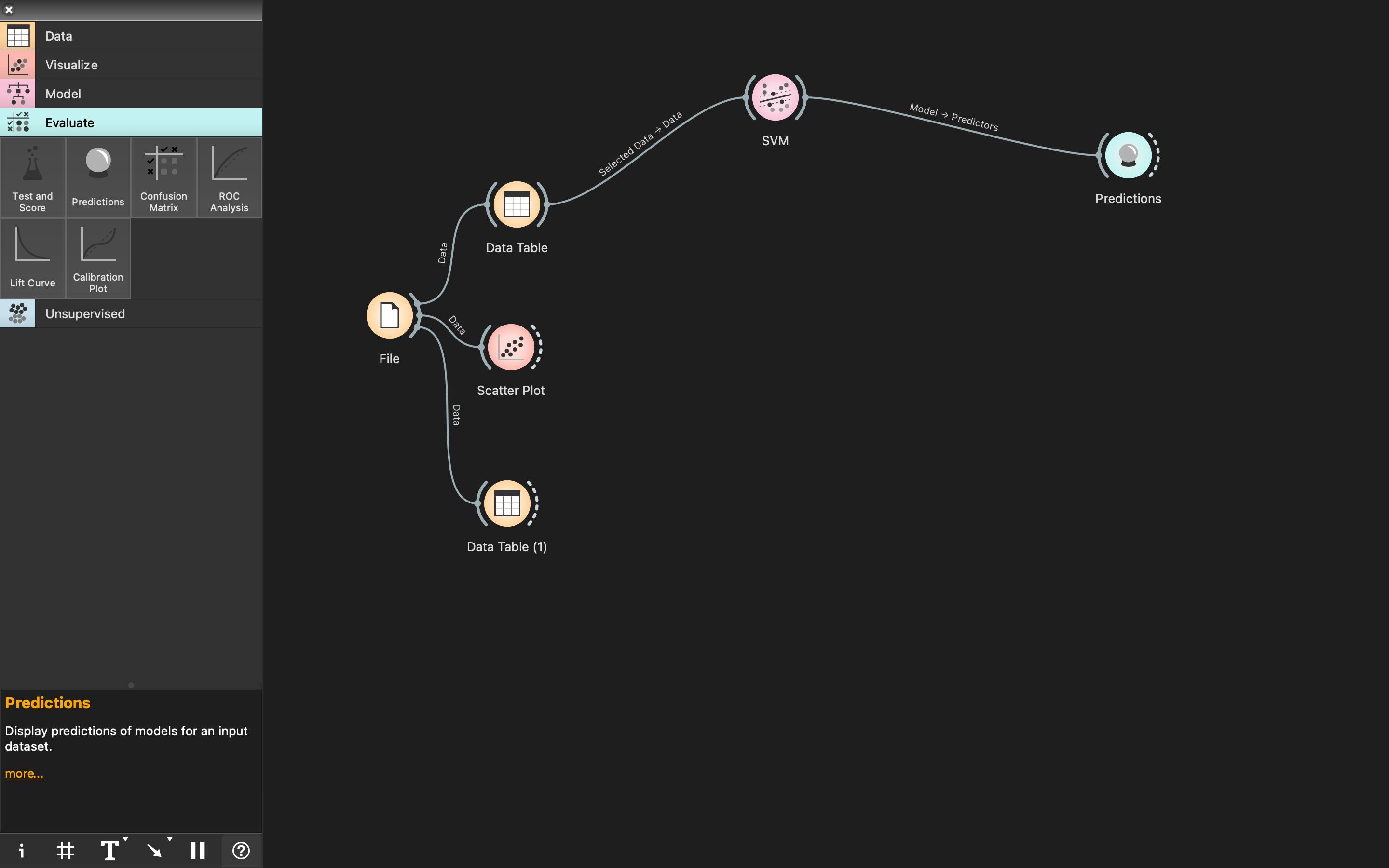
- Next, drag and drop
Predictionsfrom theEvaluatecategory to the canvas. - Connect the
SVMoutput/right arc toPredictionsinput/left arc. It would look something like this:
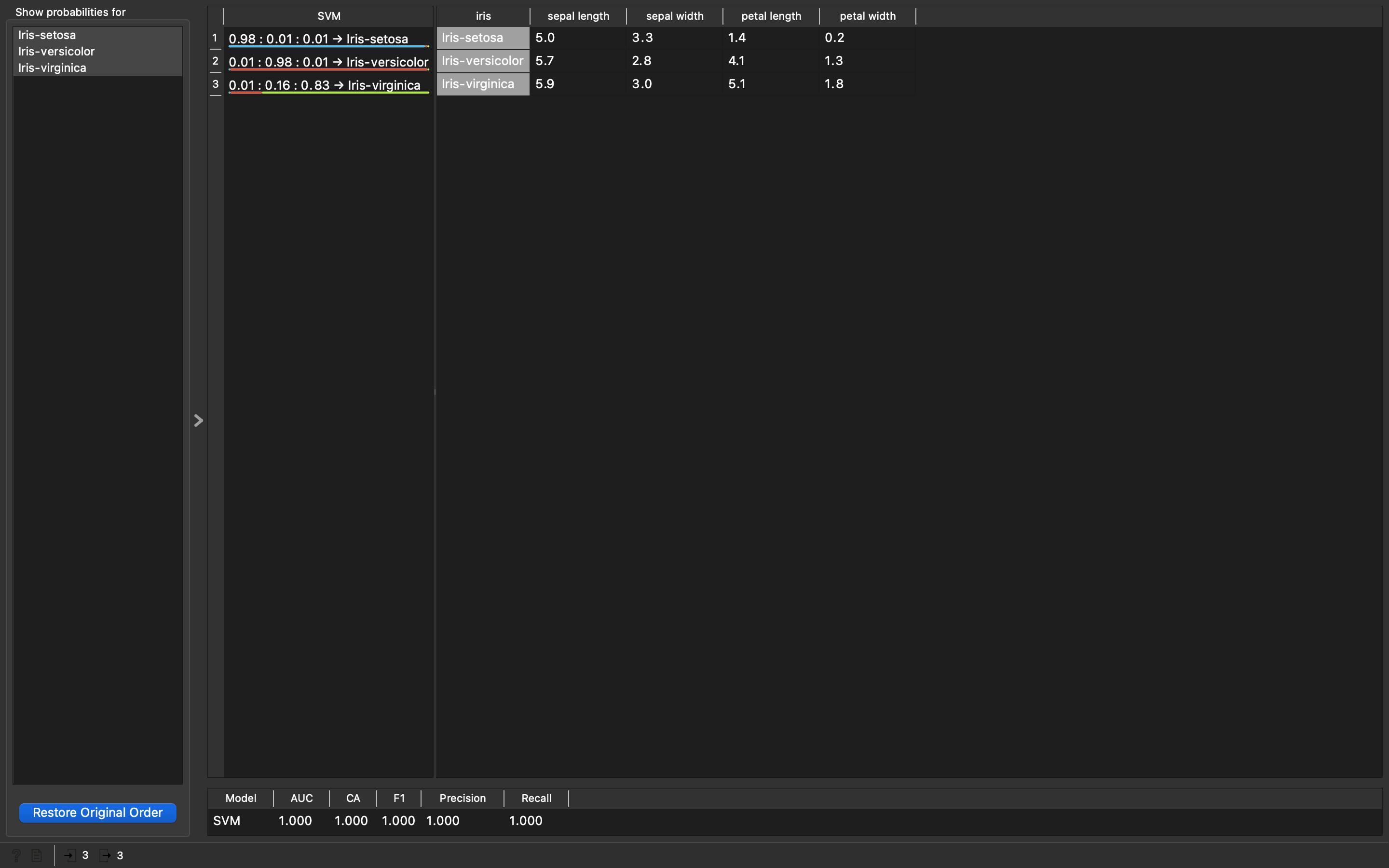
- Connect the
Data Table (1)widget (our testing sample) to thePredictionswidget. Double click on thePredictionswidget and you will see how our training model did on the test dataset (on 3 rows that we selected).
Now, let's add 1 more model to the existing diagram and see how we can compare the results of 2 different models.
Comparing Results of Models in Orange
Follow the below steps to compare several models at once:
- Drag and drop the
KNNwidget from theModelcategory to the canvas and connect theData Tablewidget with its input arc and connect to thePredictionswidget from its output arc.
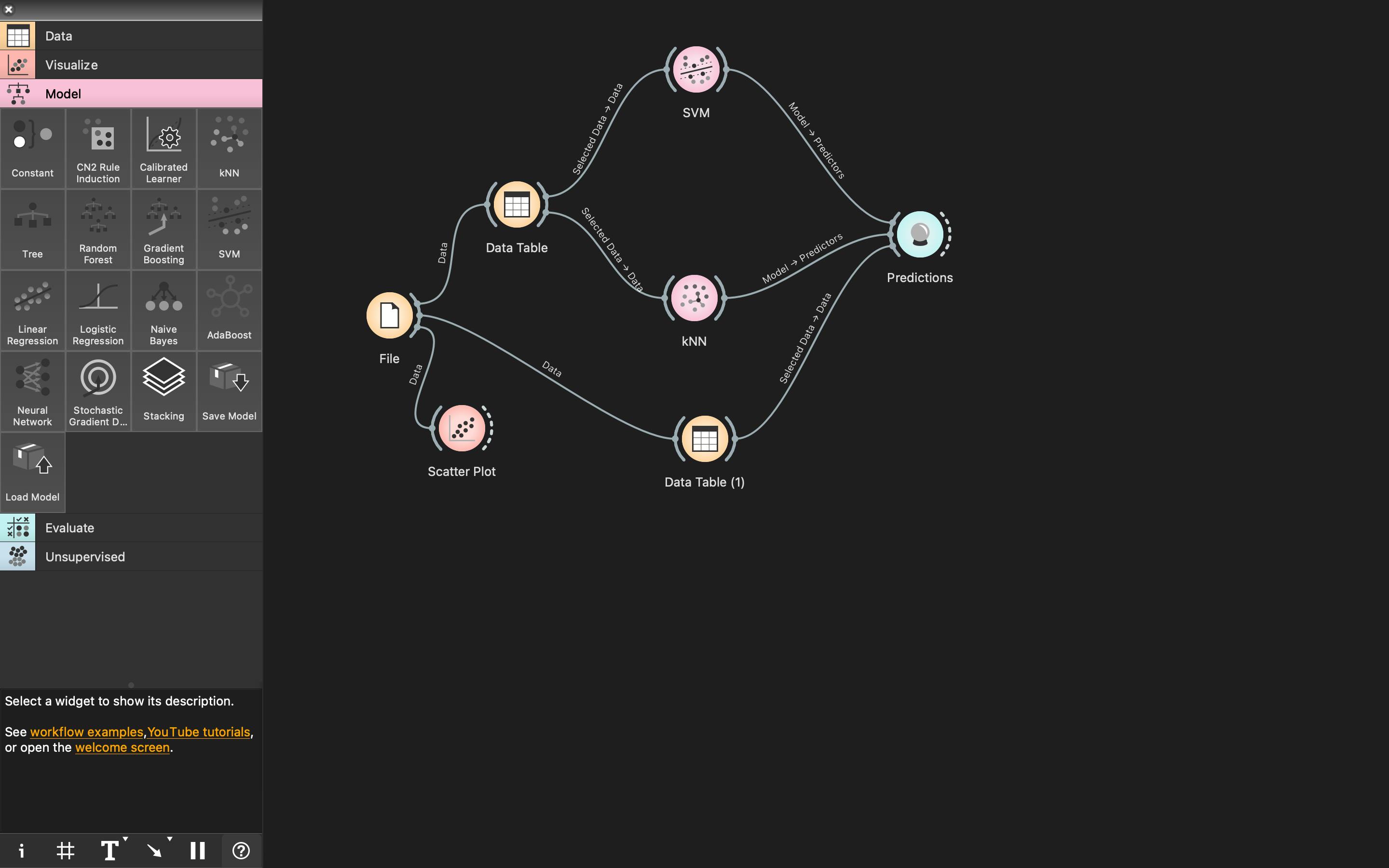
- Well, that's it, now we have 2 models connected to
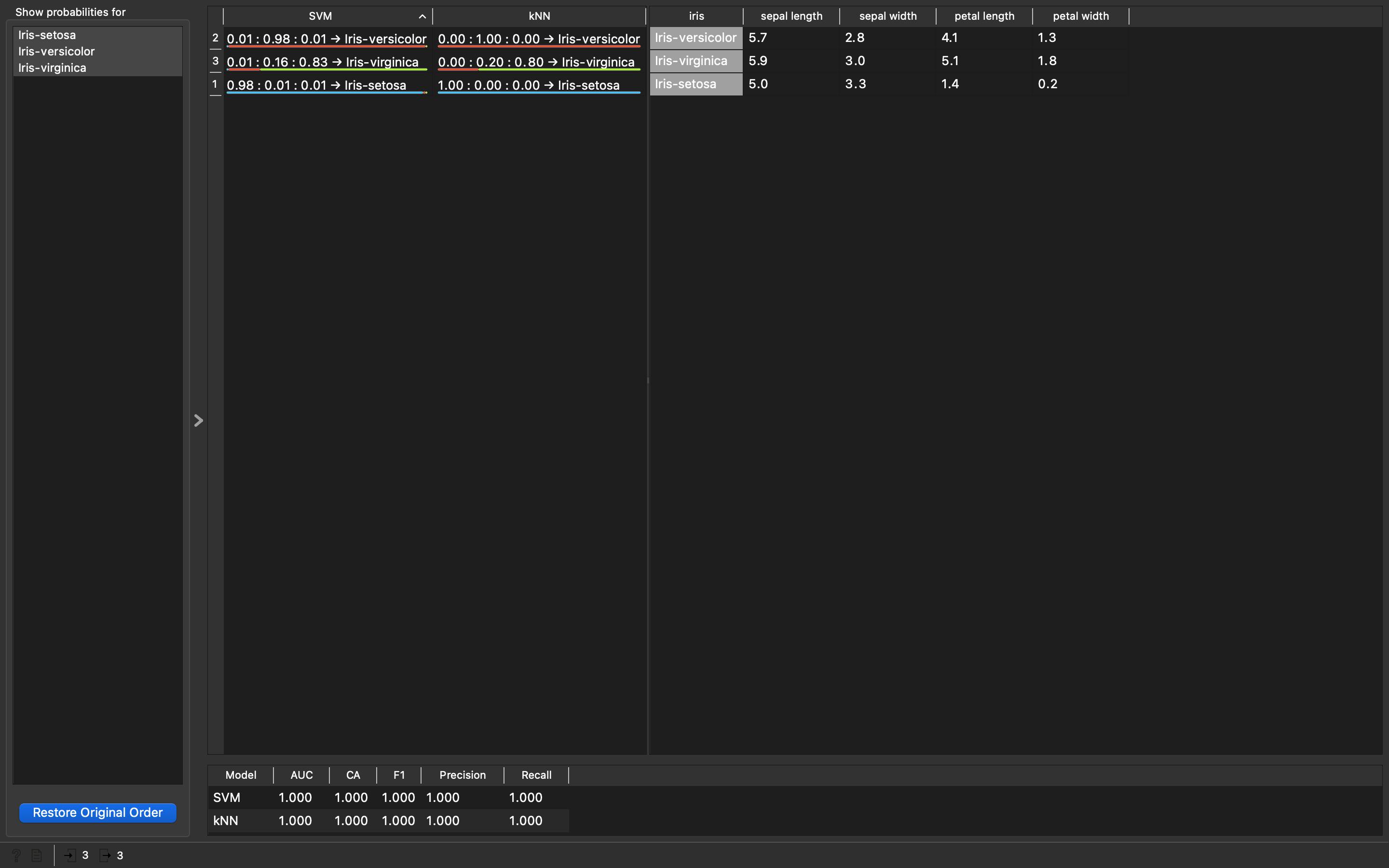
Data Table(training set) and both pointing to thePredictions. Double clickPredictionswidget and we can see and compare outputs of 2 models on the same dataset.
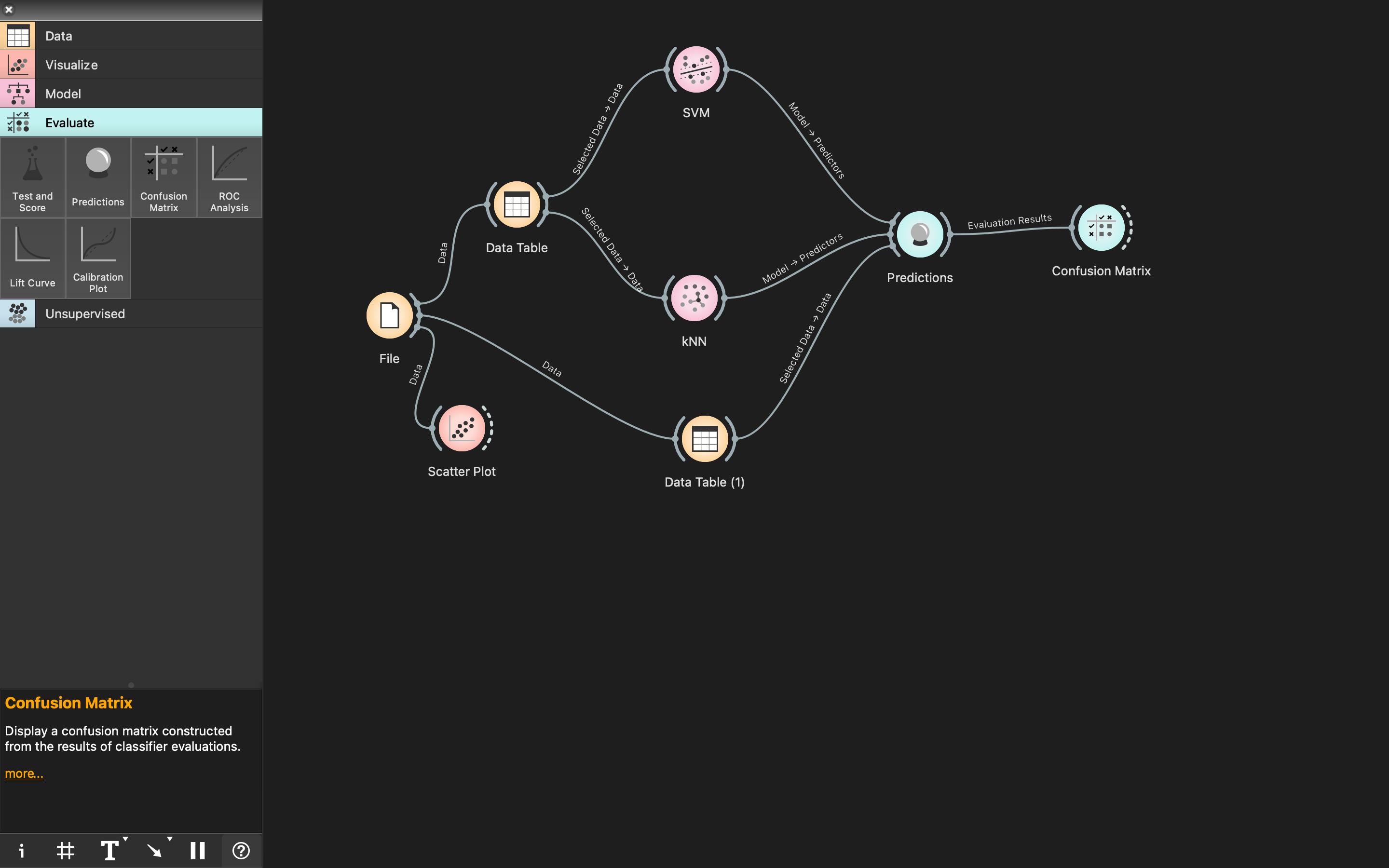
- Additionally we can also include a confusion matrix. Drag and drop the
Confusion Matrixwidget from theEvaluatecategory and connect thePredictionsoutput arc to its input arc.
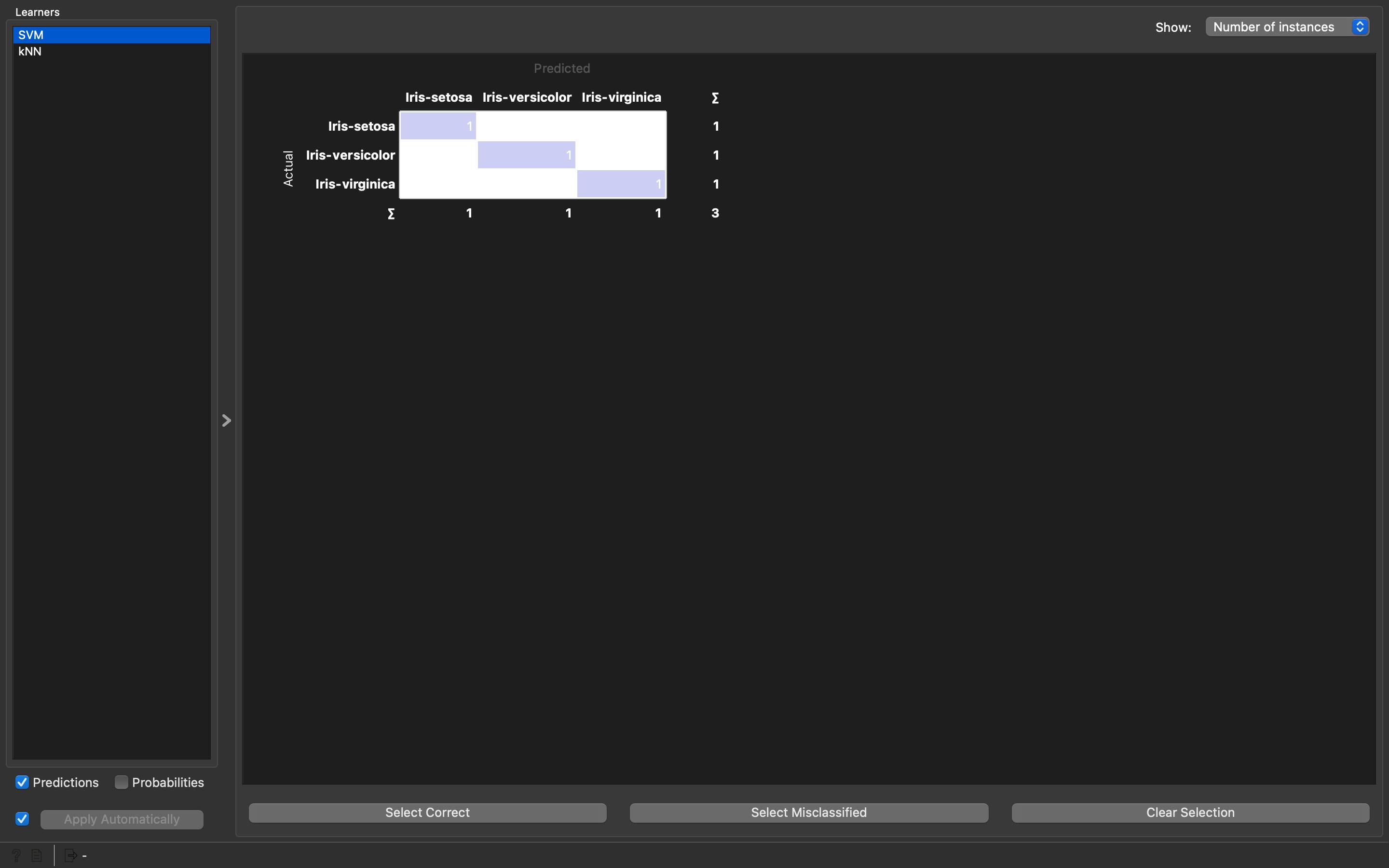
- Double click on the
Confusion Matrixwidget to see and compare the results ofSVMandKNNwidget models.
What Can Be Done From Here?
Well, these were the most basics of operations you can do to achieve a functional machine learning model and analyse the dataset. You can add more models and evaluate different widgets from the Evaluate category.
Using the Orange tool, you can easily apply different machine learning classifiers to the dataset and make a comparative study to find out the best classifier for the given dataset.
Orange can be used for unsupervised learning, image analytics, time series analysis, data mining, bioinformatics, etc.
Go and try your hands on different functionalities it offers and how it can reduce the task of writing code to no-code for simple yet complex machine learning tasks.
Explore their official documentation for more tutorials and see how it fits your needs. Visit here.
Just starting your Open Source Journey? Don't forget to check Hello Open Source
Need inspiration or a different perspective on the Python projects or just out there to explore? Check Awesome Python Repos
Want to make a simple and awesome game from scratch? Check out PongPong
Want to
++your GitHub Profile README? Check out Quote - README
Till next time!
Namaste 🙏