




Feeling lack of inspiration and motivation or just want to learn something new or out here for some fun !
Well, in this blog I will be sharing a script that I did over a weekend just for fun (and for a side project 😉).
What I will not discuss here:
How to Scrape ? That we will discuss !!
TechStack
- Python
- BeautifulSoup
Final Result (Before diving into the steps)
We will be saving all the scraped quotes in a text file. That would look something like this
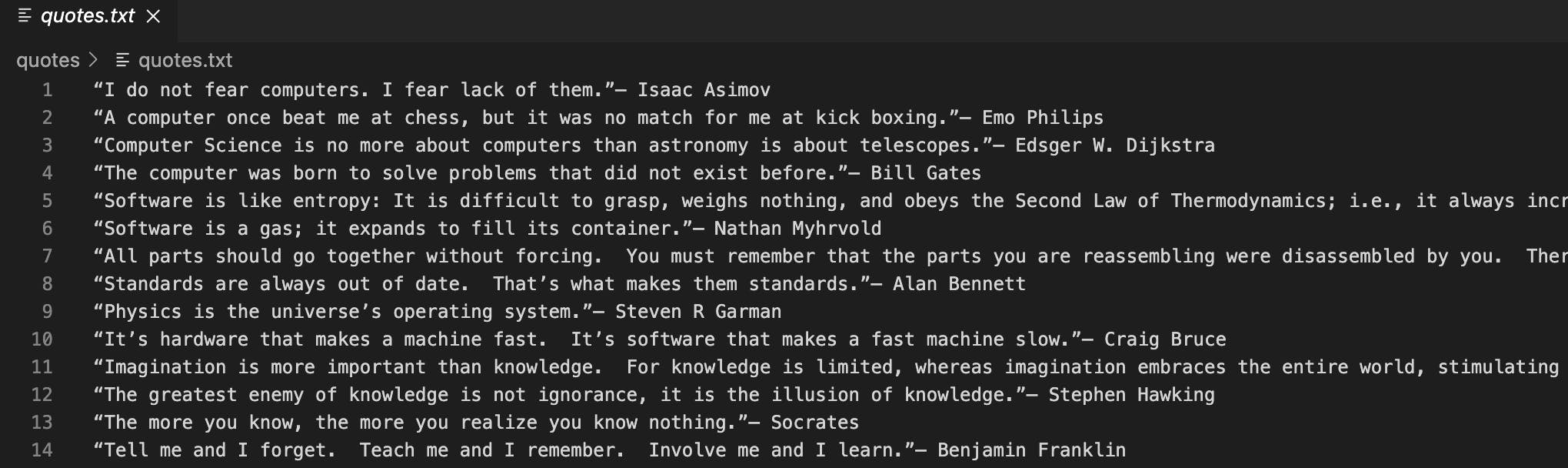
Let's Do Scraping
Analyse The Website To Scrape
As we want to scrape the inspirational quotes, we are going to get that from Great Computer Quotes
A look at webpage
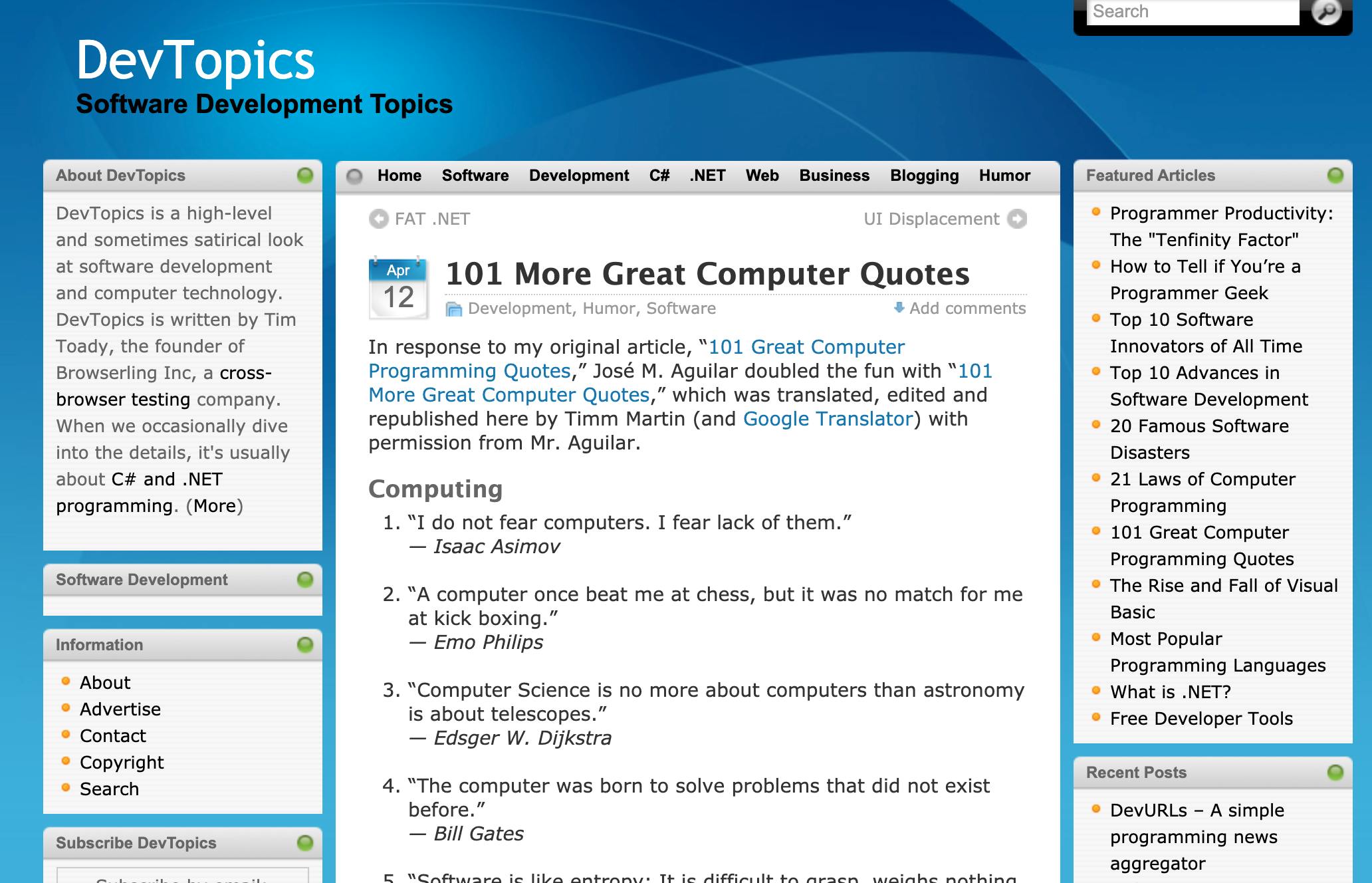
Now, we want quotes like “I do not fear computers. I fear lack of them.” - Isaac Asimov, so we should take a look at its source page first and find where is this quote present, to get the pattern (we will use that pattern later to scrape these quotes).

As we can see on page source, the quotes start from <ol> tag on line 182 and there are several <ol> tags that contains the quotes inside <li> tags. If we look further down the page or just ctrl+f or cmd+f the <ol>, we find that comments are also inside these tags.

We can ignore these comments and take only quotes present in <ol> tags with no class="commentlist" attribute.
Hence, the pattern we identified is 💡
- All quotes are inside
<ol>tags. - There are comments inside
<ol>tag as well. - We can ignore the comments by leveraging
class="commentlist"attribute of<ol>tag.
Import Required Libraries And Define Constants
Before doing the task of scraping, we need to import libraries and define some constants.
# Standard Imports
import os
from typing import List
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
from bs4.element import Tag
import oswill import python standard library, used to make directory and other OS stuff.- Then we import
Listfromtyping, to explicitly type hint some arguments passed to some functions. Requestandurlopenfrom standard libraryurllib. They would help us to get HTML data we want.BeautifulSoupfrom third-party librarybs4, this creates an easy to manage BeautifulSoup object, that represents HTML content.Tagfrombs4.element, again to be used for type hinting.
QUOTES_FILENAME = "/quotes.txt"
QUOTES_TXT_PATH = os.getcwd() + "/quotes"
QUOTES_FILE_PATH = QUOTES_TXT_PATH + QUOTES_FILENAME
QUOTES_URL = "http://www.devtopics.com/101-more-great-computer-quotes/"
QUOTES_FILENAMErepresents the filename of the text file where the quotes will be stored.QUOTES_TXT_PATHrepresents the folder where thequotes.txtwill reside.QUOTES_FILE_PATHfile path, to be used further to store data.QUOTES_URLurl to webpage we want to scrape.
Create BeautifulSoup Object
Now, we have some constants to play with, we will use QUOTES_URL to get the HTML content of the page and create a BeautifulSoup object to filter our quotes.
def get_bs4_obj(url: str) -> BeautifulSoup:
'''
Get BeautifulSoup object for given QUOTES_URL.
'''
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
html = urlopen(req).read()
bs4Obj = BeautifulSoup(html, 'html.parser')
return bs4Obj
We create a function get_bs4_obj that takes url a string type object and returns the required object bs4Obj.
Requesthelps us to bypass the security that is blocking the use ofurllibbased on the user agent. Hence, we need to giveMozillaor any other browser user agent to let us access their source page.- Then we do
urlopenwith the defined user agent inRequestand read it's content. - At last we create
BeautifulSoupobject usinghtml.parserto parse the html contents and return the required object.
It may be possible that the website has a legit reason for us to not access their page using default user agent (python's urllib), but when we try to check for if it is okay to scrape, the result status code is 200. Hence, we can scrape the site.
Steps I used to check if we are allowed to scrape the site or not
import requests #pip install requests
req = requests.get(QUOTES_URL)
print(req.status_code) #should be 200, other than 200 means scraping not/partially allowed
Filter Tags
With having bs4Obj, now it is possible to filter the HTML on <ol> tags, we can achieve that using below function
def get_ol_tags(bs4Obj: BeautifulSoup) -> List[Tag]:
'''
Get all ol tags from the bs4 obj.
Note: It is the requirement for given QUOTES_URL, it shall be different for different URL to scrap.
'''
allOL = bs4Obj.find_all('ol')
allReleventOL = list(filter(lambda ol: ol.attrs.get('class')!=['commentlist'], allOL))
return allReleventOL
See how we used the List and Tag for type hints and BeautifulSoup as well. Type hints are not mandatory and are not checked by python, these are just for developers and know that Python will always be dynamically typed !
allOL list contains all <ol> tags available in HTML. We filter them using python's inbuilt filter function on the condition that, if attribute of any <ol> tag has class equivalent to 'commentlist' then filter them out from allOL list.
Store all relevent tags in variable allReleventOL and return that (to be used by another function !)
Get Quotes
Now, we will create a generator to yield the quotes we need to save in a text file. We will be using allReleventOL variable passed to the new function.
def get_all_quotes(oltags: List[Tag]):
'''
Yield all qoutes present in OL tags.
'''
for ol in oltags:
yield ol.find('li').get_text()
It is self explanatory, here we are extracting text present in <li> tag.
We will use this generator in next section, inside another function.
Save Quotes
Here is the function !
def save_qoutes(oltags: List[Tag]):
'''
Save extracted qoutes in a text file, create a new folder if not already present
'''
global QUOTES_TXT_PATH, QUOTES_FILE_PATH
if not os.path.exists(QUOTES_TXT_PATH):
os.mkdir(QUOTES_TXT_PATH)
with open(QUOTES_FILE_PATH, 'w') as file:
for txt in get_all_quotes(oltags):
file.write(txt)
print(f'All Quotes written to file: {QUOTES_FILE_PATH}')
We take global constants QUOTES_TXT_PATH and QUOTES_FILE_PATH to be used while writing to the file. We check if the directory exists or not (the folder where we will save our file). Then we open the file in the created directory (if not exists).
Now here comes the use of generator, we call generator on each <ol> tag that yields text of <li> tags. Something fishy here ? Yeah you got it right, we are using ol.find('li') that should return first <li> tag, but how come all <li> tags are getting returned ? Because it is the error in HTML file !
<li>“I do not fear computers. I fear lack of them.”<br /><em>— Isaac Asimov<br /> </em>
Here, there is no </li> tag to mark its end !! Hence it takes the start of <li> and marks the end whenever it encounters a </li> tag, which happens to be before </ol> tag 😄

Main
Now the script to execute the code
if __name__ == "__main__":
bs4Obj = get_bs4_obj(QUOTES_URL)
olTags = get_ol_tags(bs4Obj)
save_qoutes(olTags)
If you check now, the quotes should be appearing in the file created quotes.txt inside the folder /quotes.
Well, that was it, if you followed this then you now know the gist of general process for web scraping and how to scrape Inspirational Quotes !
It was just a drop in the ocean full of different functionalities you can achieve with web scraping, but the general idea remains the same:
- Get the website we want to scrape.
- Analyse the required components we need and find the pattern.
- Create BeautifulSoup object to ease the process and access HTML without much problem.
- Create small functions to get the task done.
- Finally integrate all function and see the magic of the script !
Full python script can be found here.
GitHub action where this script is used. Would love to hear your feedback on this as well.
Just starting you Open Source Journey ? Don't forget to check out Hello Open Source
Want to make a simple and awesome game from scratch ? Check PongPong
Till next time !
Namaste 🙏